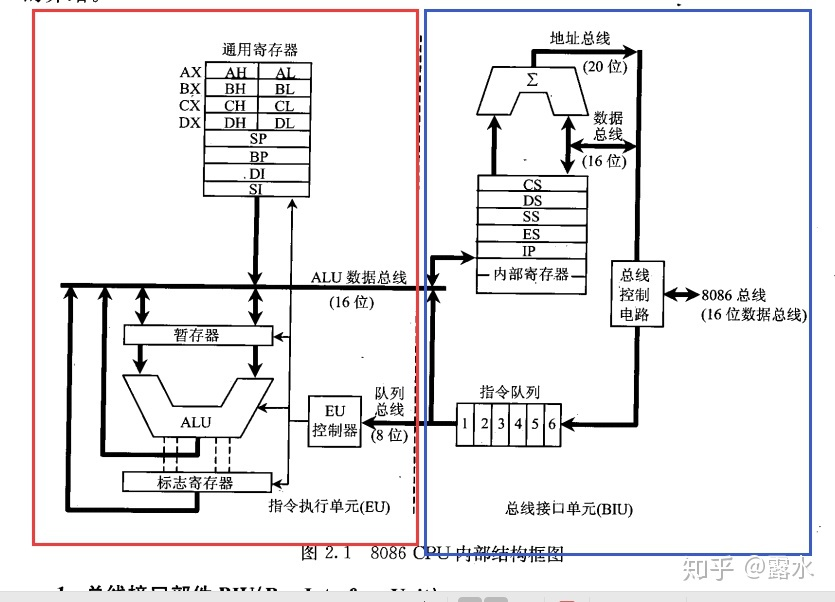
一个典型的CPU由运算器、控制器、寄存器(CPU工作原理)等器件构成,这些器件靠内部总线相连。
第一章所说的总线,相对于CPU内部来说是外部总线。内部总线实现CPU内部各个器件之间的联系,外部总线实现CPU和主板上其他器件的联系。简单地说,在CPU中:
运算器进行信息处理;
寄存器进行信息存储;
控制器控制各种器件进行工作;
内部总线连接各种器件,在它们之间进行数据的传送。
不同的CPU,寄存器的个数、结构是不相同的。8086CPU有14个寄存器,每个寄存器有一个名称。这些寄存器是:AX、BX、CX、DX、SI、DI、SP、BP、IP、CS、SS、 DS、ES、PSW。
2.1 通用寄存器8086CPU的所有寄存器都是16位的,可以存放两个字节。
AX、BX、CX、DX这4个寄存器通常用来存放一般性的数据,被称为通用寄存器。
以AX为例,寄存器的逻辑结构如图2.1所示。
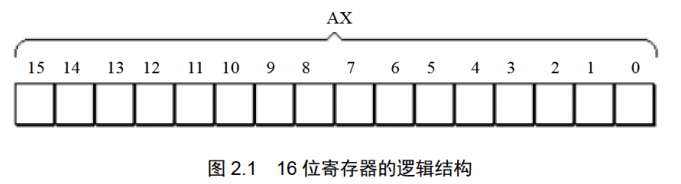
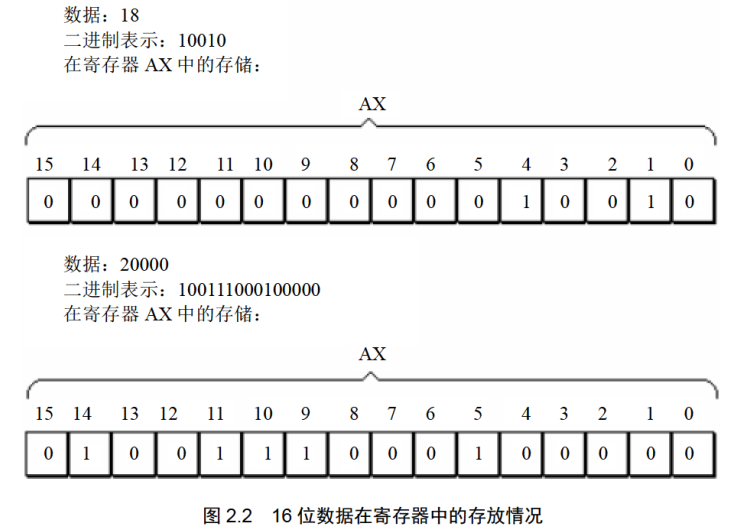
一个16位寄存器可以存储一个16位的数据。如下图
8086CPU的上一代CPU中的寄存器都是8位的,为了保证兼容,使原来基于上代CPU编写的程序稍加修改就可以运行在8086之上,8086CPU的AX、BX、CX、DX这4个寄存器都可分为两个可独立使用的8位寄存器来用:
AX可分为AH(高8位)和AL(低8位);BX可分为BH(高8位)和BL(低8位);CX可分为CH(高8位)和CL(低8位);DX可分为DH(高8位)和DL(低8位);以AX为例,8086CPU的16位寄存器分为两个8位寄存器的情况如图2.3所示。
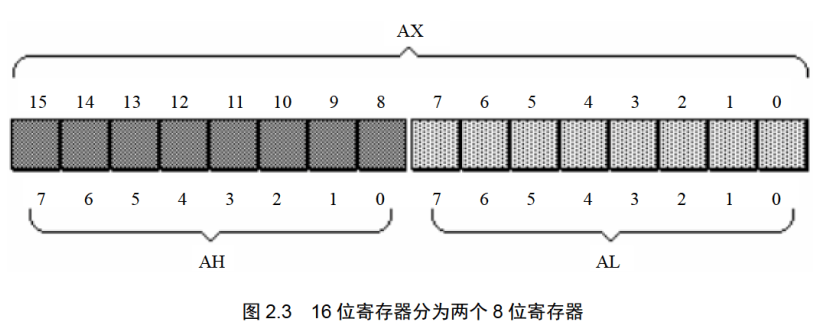
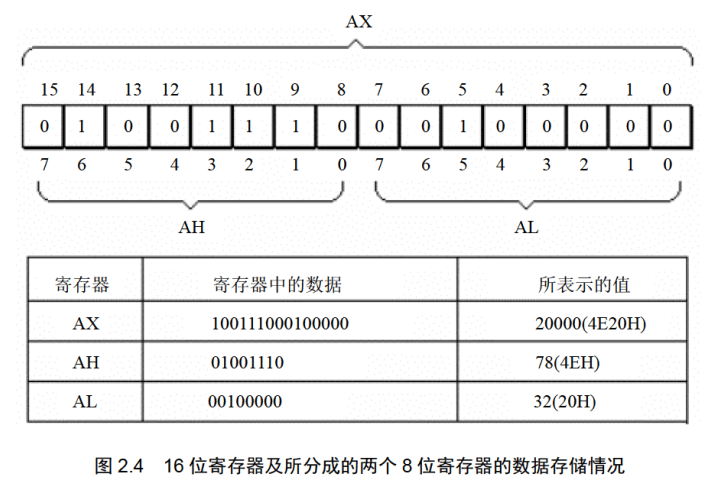
AX的低8位(0位〜7位)构成了AL寄存器,高8位(8位〜15位)构成了AH寄存器。
AH和AL寄存器是可以独立使用的8位寄存器。图2.4展示了16位寄存器及它所分成的两个8位寄存器的数据存储的情况。
8086CPU可以一次性处理以下两种尺寸的数据。
字节:记为byte, 一个字节由8个bit组成,可以存在8位寄存器中。
字:记为word, 一个字由两个字节组成,这两个字节分别称为这个字的高位字节和低位字节,如图2.5所示。
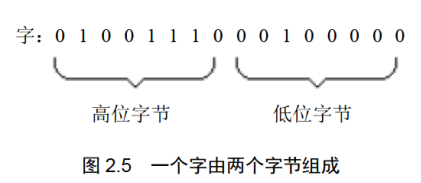
一个字可以存在一个16位寄存器中,这个字的高位字节和低位字节自然就存在这个寄存器的高8位寄存器和低8位寄存器中。
关于数制的讨论
任何数据,到了计算机中都是以二进制的形式存放的。为了描述不同的问题,又经常将它们用其他的进制来表示。比如图2.4中寄存器AX中的数据是0100111000100000,这就是AX中的信息本身,可以用不同的逻辑意义来看待它。可以将它看作一个数值,大小是20000。
当然,二进制数0100111000100000本身也可表示一个数值的大小,但人类习惯的是十进制,用十进制20000表示可以使我们直观地感受到这个数值的大小。
十六进制数的一位相当于二进制数的四位,如0100111000100000可表示成:4(0100)、E(1110)、2(0010)、0(0000)四位十六进制数。
一个内存单元可存放8位数据,CPU中的寄存器又可存放n个8位的数据。也就是说,计算机中的数据大多是由1〜N个8位数据构成的。很多时候,需要直观地看出组成数据的各个字节数据的值,用十六进制来表示数据可以直观地看出这个数据是由哪些8位数据构成的。比如20000写成4E20就可以直观地看出,这个数据是由4E和20两个8位数据构成的,如果AX中存放4E20,则AH里是4E, AL里是20。这种表示方法便于许多问题的直观分析。在以后的课程中,我们多用十六进制来表示一个数据。
在以后的课程中,为了区分不同的进制,在十六进制表示的数据的后面加H,在二进制表示的数据后面加B,十进制表示的数据后面什么也不加。如:可用3种不同的进制表示图2.4中AX里的数据,十进制:20000,十六进制:4E20H,二进制:0100111000100000B。
2.3 初识汇编指令通过汇编指令控制CPU进行工作,看一下表2.1中的几条指令。
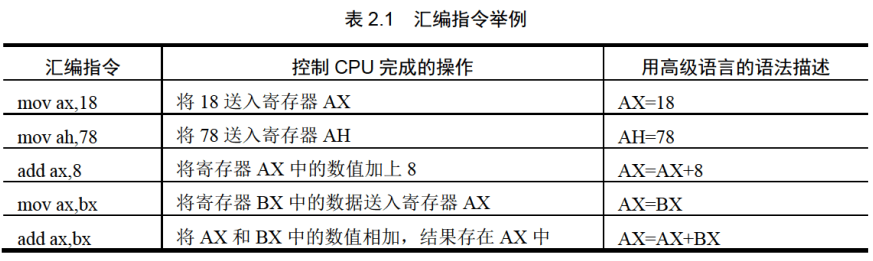
在写一条汇编指令或一个寄存器的名称时不区分大小写。如:mov ax,18和MOV AX,18的含义相同;bx和BX的含义相同。
接下来看一下CPU执行表2.2中所列的程序段中的每条指令后,对寄存器中的数据进行的改变。
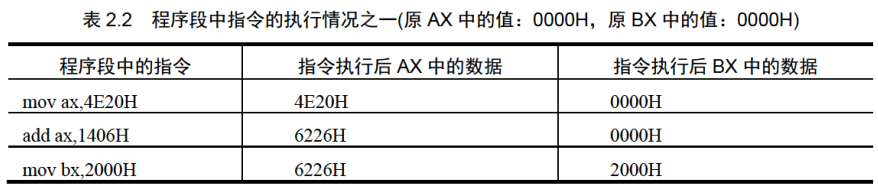

问题2.1指令执行后AX中的数据为多少?思考后看分析。
分析:
程序段中的最后一条指令add ax,bx,在执行前ax和bx中的数据都为8226H,相加后所得的值为:1044CH,但是ax为16位寄存器,只能存放4位十六进制的数据,所以最高位的1不能在ax中保存,ax中的数据为:044CH。
表2.3程序段中指令的执行情况之二(原AX中的值:0000H,原BX中的值:0000H)
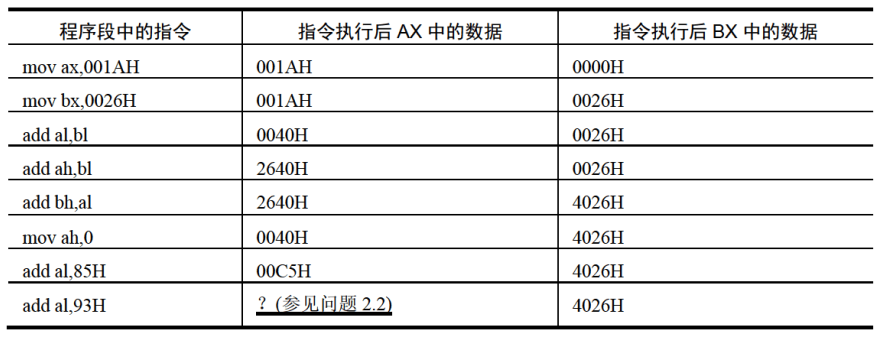
问题2.2指令执行后AX中的数据为多少?思考后看分析。
分析:
程序段中的最后一条指令add al,93H,在执行前,al中的数据为C5H,相加后所得的值为:158H,但是al为8位寄存器,只能存放两位十六进制的数据,所以最高位的1丢失,ax中的数据为:0058H。(这里的丢失,指的是进位值不能在8位寄存器中保存,但是CPU并不真的丢弃这个进位值。)
注意,此时al是作为一个独立的8位寄存器来使用的,和ah没有关系。
在进行数据传送或运算时,要注意指令的两个操作对象的位数应当是一致的,例如:
mov ax,bxmov bx,exmov ax,18Hmov al,18Hadd ax,bxadd ax,20000
以上都是正确的指令,而:
mov ax,bl (在8位寄存器和16位寄存器之间传送数据)mov bh,ax (在16位寄存器和8位寄存器之间传送数据)mov al,20000 (8位寄存器最大可存放值为255的数据)add al,100H (将一个高于8位的数据加到一个8位寄存器中)
等都是错误的指令,错误的原因都是指令的两个操作对象的位数不一致。
2.4 CPU 16位结构CPU访问内存单元时,要给出内存单元的地址。
所有的内存单元构成的存储空间是一个一维的线性空间,每一个内存单元在这个空间中都有唯一的地址,我们将这个唯一的地址称为物理地址。
CPU通过地址总线送入存储器的,必须是一个内存单元的物理地址。
在CPU向地址总线上发出物理地址之前,必须要在内部先形成这个物理地址。
不同的CPU可以有不同的形成物理地址的方式。我们现在讨论8086CPU是如何在内部形成内存单元的物理地址的。
我们说8086CPU的上一代CPU(8080、8085)等是8位机,而8086是16位机,也可以说8086是16位结构的CPU。
那么什么是16位结构的CPU呢?
概括地讲,16位结构(16位机、字长为16位等常见说法,与16位结构的含义相同) 描述了一个CPU具有下面几方面的结构特性。
运算器一次最多可以处理16位的数据;寄存器的最大宽度为16位;寄存器和运算器之间的通路为16位。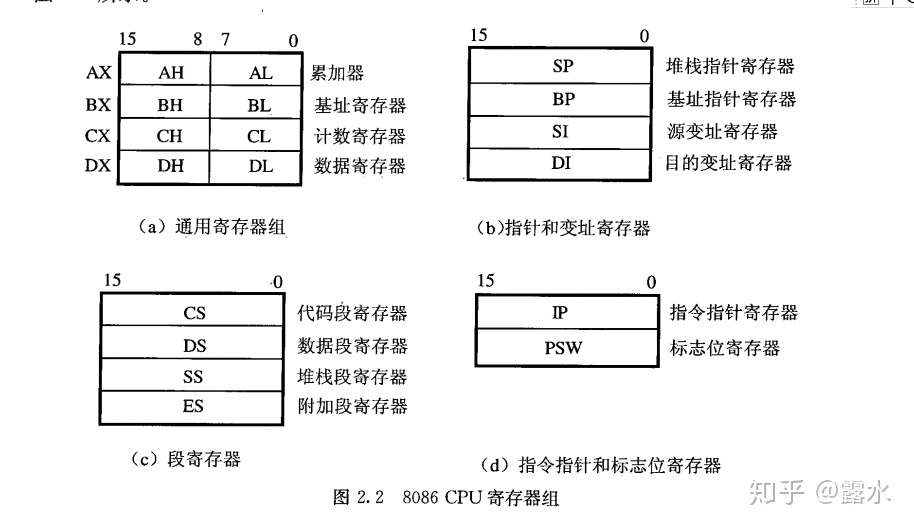
8086是16位结构的CPU,这也就是说,在8086内部,能够一次性处理、传输、暂时存储的信息的最大长度是16位的。
内存单元的地址在送上地址总线之前,必须在CPU中处理、传输、暂时存放,对于16位CPU,能一次性处理、传输、暂时存储16位的地址。
2.5 8086CPU给出物理地址的方法8086CPU有20位地址总线,可以传送20位地址,达到1MB寻址能力。
8086CPU又是16位结构,在内部一次性处理、传输、暂时存储的地址为16位。
从8086CPU的内部结构来看,如果将地址从内部简单地发岀,那么它只能送出16位的地址,表现出的寻址能力只有64KB。
8086CPU采用一种在内部用两个16位地址合成的方法来形成一个20位的物理地址。
8086CPU相关部件的逻辑结构如图2.6所示。
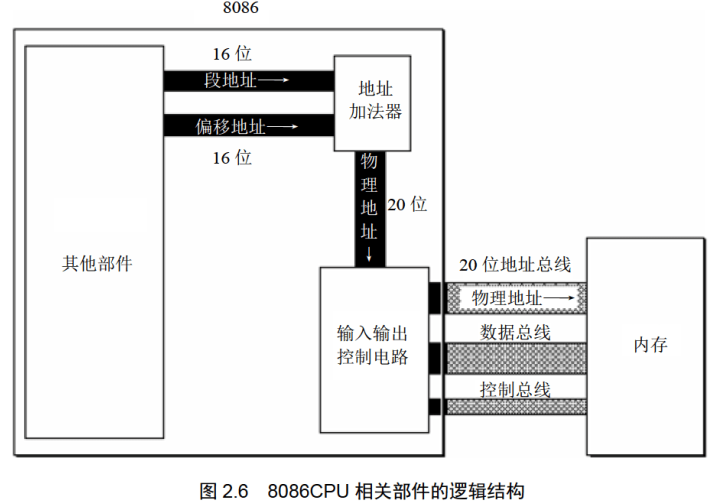
如图2.6所示,当8086CPU要读写内存时:
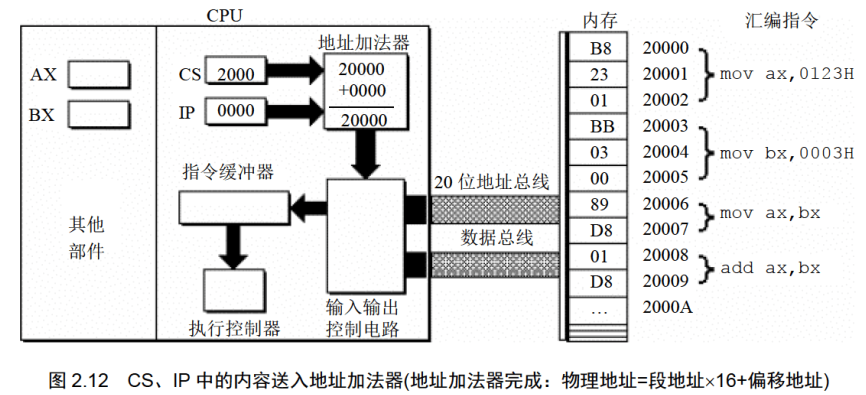
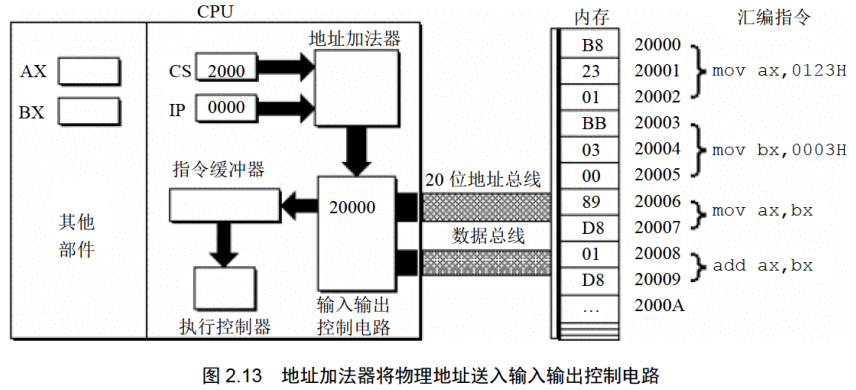
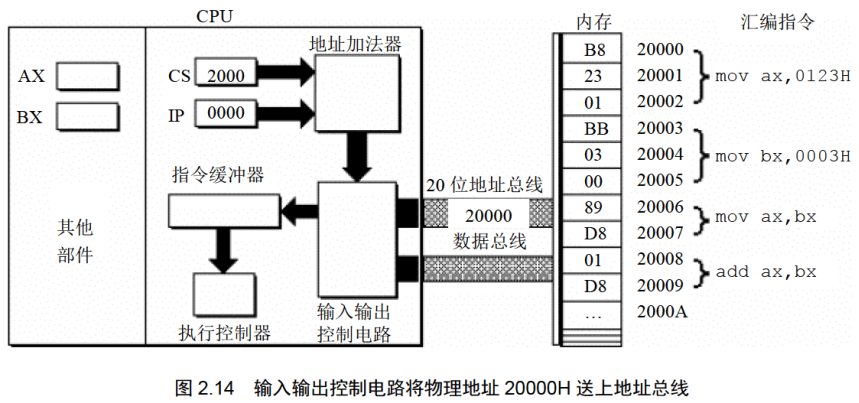
(1)CPU中的相关部件提供两个16位的地址,一个称为段地址,另一个称为偏移地址;(2)段地址和偏移地址通过内部总线送入一个称为地址加法器的部件;(3)地址加法器将两个16位地址合成为一个20位的物理地址;(4)地址加法器通过内部总线将20位物理地址送入输入输出控制电路;(5)输入输出控制电路将20位物理地址送上地址总线:(6)20位物理地址被地址总线传送到存储器。
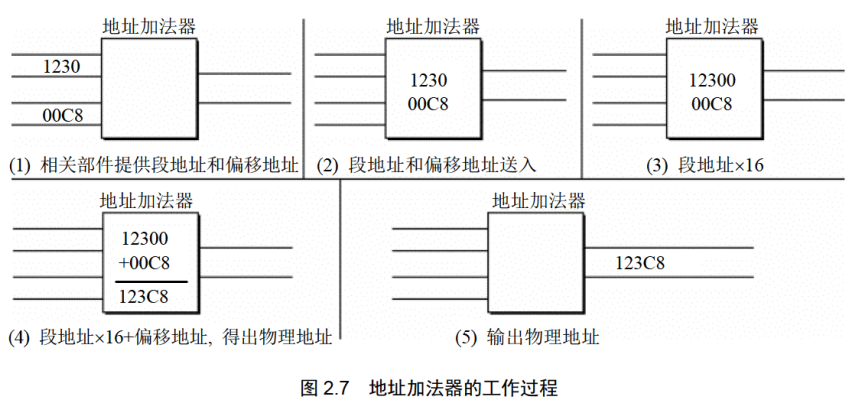
地址加法器采用物理地址=段地址X16+偏移地址的方法用段地址和偏移地址合成物理地址。
例如,8086CPU要访问地址为123C8H的内存单元,此时,地址加法器的工作过程如图2.7所示(图中数据皆为十六进制表示)。
段地址 x 16引发的讨论
“段地址xl6”有一个更为常用的说法是左移4位。计算机中的所有信息都是以二进制的形式存储的,段地址当然也不例外。机器只能处理二进制信息,“左移4位”中的位,指的是二进制位。
我们看一个例子,一个数据为2H,二进制形式为10B,对其进行左移运算:

观察上面移位次数和各种形式数据的关系,我们可以发现:
(1)一个数据的二进制形式左移1位,相当于该数据乘以2;
(2)一个数据的二进制形式左移N位,相当于该数据乘以2的N次方;
(3)地址加法器如何完成段地址 x 16的运算?就是将以二进制形式存放的段地址左移4位。
进一步思考,我们可看出:一个数据的十六进制形式左移1位,相当于乘以16; 一个数据的十进制形式左移1位,相当于乘以10; 一个X进制的数据左移1位,相当于乘以X。
2.6 “段地址x16+偏移地址=物理地址”的本质含义本质含义是:CPU在访问内存时,用一个基础地址(段地址X16)和一个相对于基础地址的偏移地址相加,给岀内存单元的物理地址。
更一般地说,8086CPU的这种寻址功能是“基础地址+偏移地址=物理地址"寻址模式的一种具体实现方案。
8086CPU中,段地址 x 16可看作是基础地址。
两个比喻进一步说明:
第一个比喻说明“基础地址+偏移地址=物理地址”的思想。

(1) 从学校走2826m到图书馆。这2826m可以认为是图书馆的物理地址。(2) 从学校走2000m到体育馆,从体育馆再走826m到图书馆。第一个距离2000m, 是相对于起点的基础地址,第二个距离826m是相对于基础地址的偏移地址(以基础地址为起点的地址)。
第一种方式是直接给出物理地址2826m,而第二种方式是用基础地址和偏移地址相加来得到物理地址的。
第二个比喻进一步说明“段地址X16+偏移地址=物理地址”的思想。
我们为上面的例子加一些限制条件,比如,只能通过纸条来互相通信,你问我图书馆的地址我只能将它写在纸上告诉你。
显然,我必须有一张可以容纳4位数据的纸条,才能写下2826这个数据。
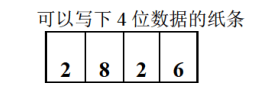
可不巧的是,我没有能容纳4位数据的纸条,仅有两张可以容纳3位数据的纸条。这样我只能以这种方式告诉你2826这个数据。
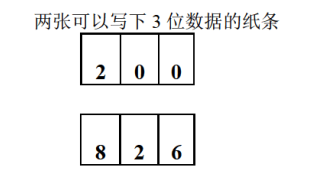
在第一张纸上写上200(段地址),在第二张纸上写上826(偏移地址)。假设我们事前对这种情况乂有过相关的约定:你得到这两张纸后,做这样的运算:
200(段地址)x 10+826(偏移地址)=2826(物理地址)
8086CPU就是这样一个只能提供两张3位数据纸条的CPU。
2.7 段、段寄存器首先说一个错误的概念:“段地址”这个名称中包含着“段”的概念。这种说法可能对一些初学者产生误导,使人误以为内存被划分成了一个一个的段,每一个段有一个段地址。这种认识,将影响以后对汇编语言的深入理解和灵活应用。
内存并没有分段,段的划分来自于CPU,由于8086CPU用“基础地址(段地址 x 16)+ 偏移地址=物理地址”的方式给出内存单元的物理地址,使得我们可以用分段的方式来管理内存。
如图2.9所示,我们可以认为:地址10000H〜100FFH的内存单元组成一个段,该段的起始地址(基础地址)为10000H,段地址为1000H,大小为100H;
我们也可以认为地址10000H〜1007FH、10080H-100FFH的内存单元组成两个段,它们的起始地址(基础地址)为:10000H和10080H,段地址为:1000H和1008H,大小都为80H。
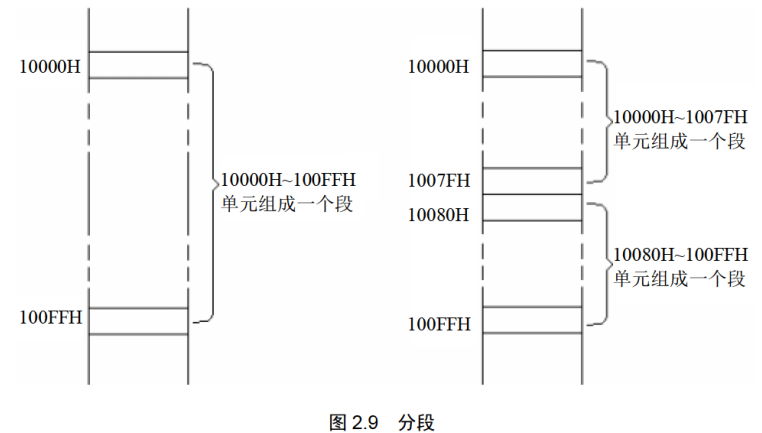
在编程时可以根据需要,将若干地址连续的内存单元看作一个段,用段地址 x 16定位段的起始地址(基础地址),用偏移地址定位段中的内存单元。
有两点需要注意:
1、段地址 X 16必然是16的倍数,所以一个段的起始地址也一定是16的倍数;
2、偏移地址为16位,16位地址的寻址能力为64KB,所以一个段的长度最大为64KB。
内存单元地址小结
CPU访问内存单元时,必须向内存提供内存单元的物理地址。
8086CPU在内部用段地址和偏移地址移位相加的方法形成最终的物理地址。
思考下面的两个问题。
(1)观察下面的地址,你有什么发现?

结论:CPU可以用不同的段地址和偏移地址形成同一个物理地址。
比如CPU要访问21F60H单元 则它给出的段地址SA和偏移地址EA满足SAx16+EA=21F60H即可。
(2)如果给定一个段地址,仅通过变化偏移地址来进行寻址,最多可定位多少个内存单元?
结论:偏移地址16位,变化范围为0〜FFFFH,仅用偏移地址来寻址最多可寻64KB个内存单元。
比如给定段地址1000H,用偏移地址寻址,CPU的寻址范围为:10000H〜1FFFFH。
在8086PC机中,存储单元的地址用两个元素来描述,即段地址和偏移地址。
“数据在21F60H内存单元中。”这句话对于8086PC机一般不这样讲,取而代之的是两种类似的说法:
①数据存在内存2000:1F60单元中;
②数据存在内存的2000H段中的1F60H单元中。这两种描述都表示“数据在内存21F60H单元中”。
可以根据需要,将地址连续、起始地址为16的倍数的一组内存单元定义为一个段。
前面讲到,8086CPU在访问内存时要由相关部件提供内存单元的段地址和偏移地址,送入地址加法器合成物理地址。
这里,需要看一下,是什么部件提供段地址?
段地址在8086CPU的段寄存器中存放。
8086CPU有4个段寄存器:CS、DS、SS、ES。
当8086CPU要访问内存时,由这4个段寄存器提供内存单元的段地址。
2.8 CS、IP及其修改指令CS和IP是8086CPU中两个最关键的寄存器,它们指示了CPU当前要读取指令的地址。
CS为代码段寄存器,IP为指令指针寄存器,从名称上我们可以看出它们和指令的关系。
在8086PC机中,任意时刻,设CS中的内容为M, IP中的内容为N, 8086CPU将从内存M x 16 + N单元开始,读取一条指令并执行。
也可以这样表述:8086机中,任意时刻,CPU将CS:IP指向的内容当作指令执行。
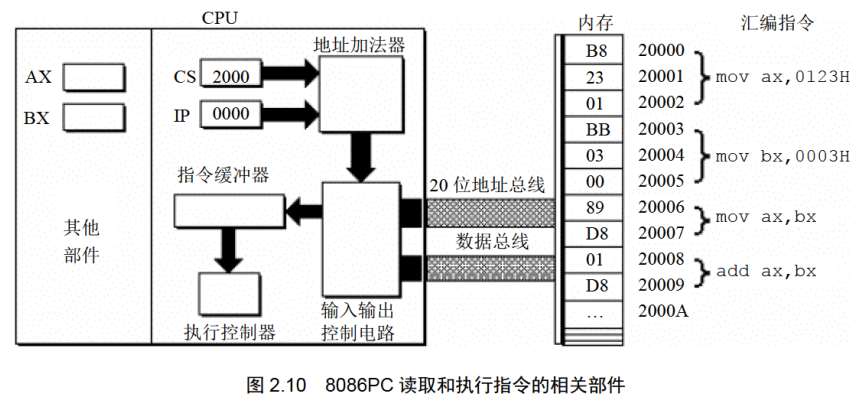
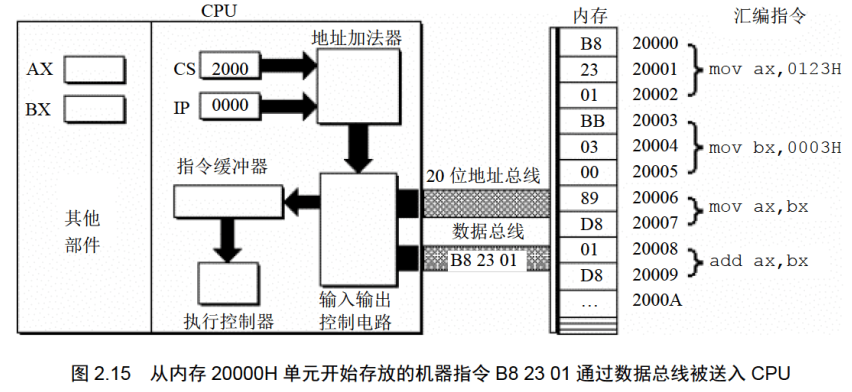
图2.10说明如下。
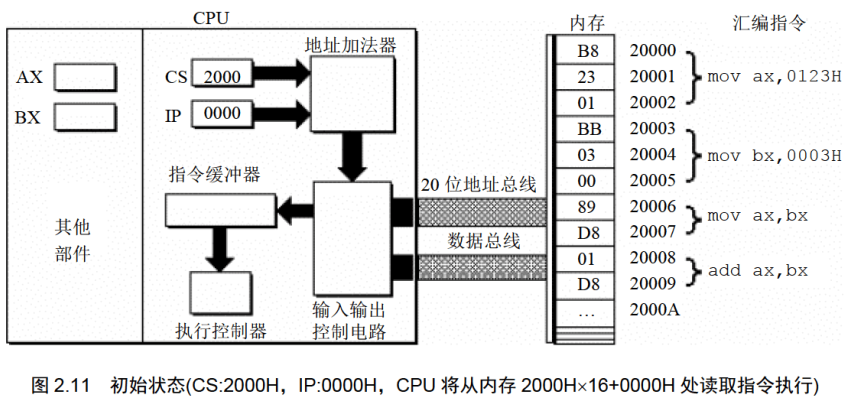
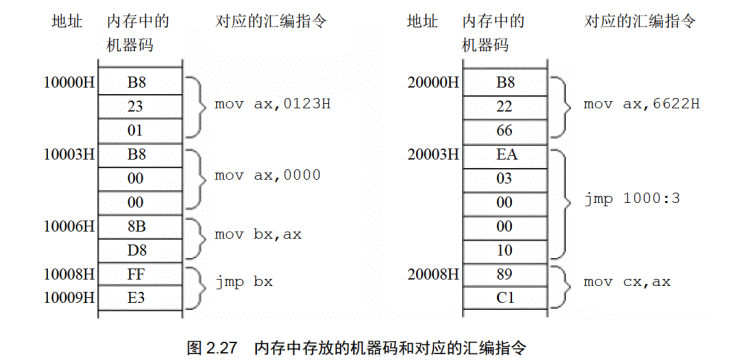
(1)8086CPU当前状态:CS中的内容为2000H, IP中的内容为0000H;
(2)内存20000H-20009H单元存放着可执行的机器码;
(3)内存20000H〜20009H单元中存放的机器码对应的汇编指令如下。
地址:20000H~20002H,内容:B8 23 01,长度:3Byte,对应汇编指令:mov ax,0123H
地址:20003H~20005H,内容:BB 03 00,长度:3Byte,对应汇编指令:mov bx,0003H
地址:20006H~20007H,内容:89 D8,长度:2Byte,对应汇编指令:mov ax,bx
地址:20008H~20009H,内容:01 D8,长度:2Byte,对应汇编指令:add ax,bx
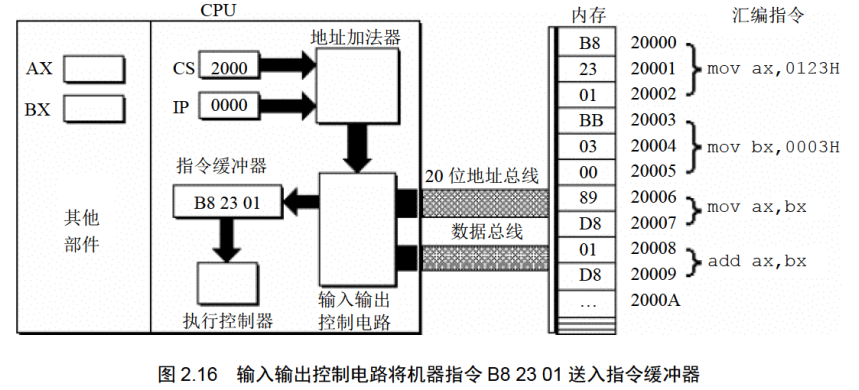
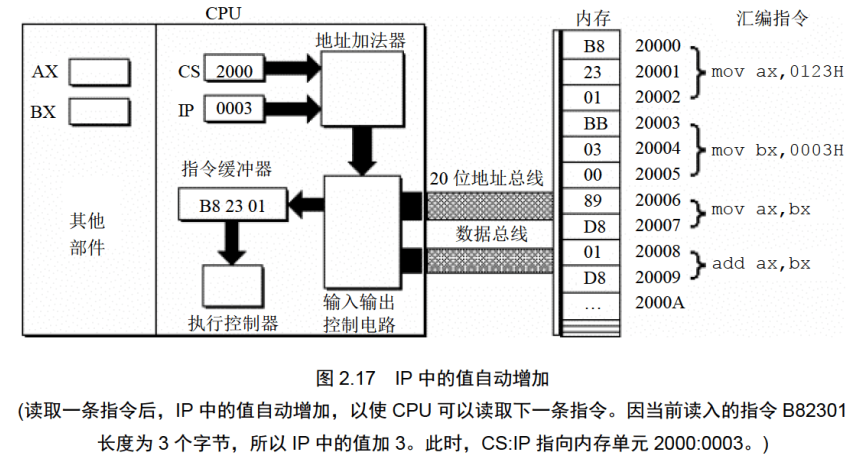
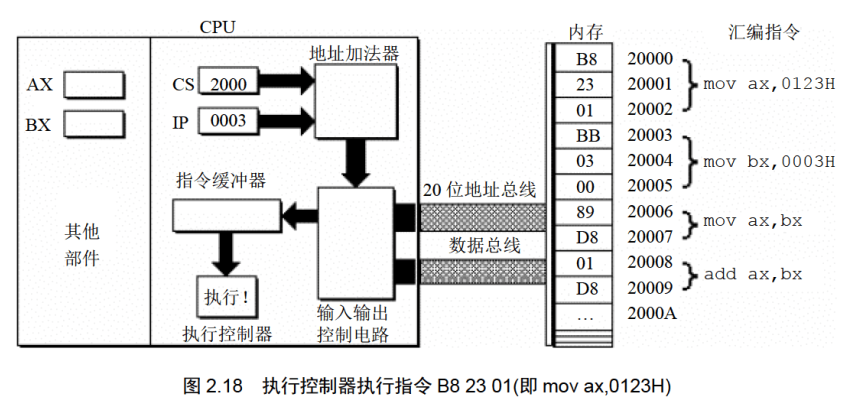
下面的一组图(图2.11〜图2.19),以图2.10描述的情况为初始状态,展示了8086CPU 读取、执行一条指令的过程。
注意每幅图中发生的变化(下面对8086CPU的描述,是在逻辑结构、宏观过程的层面上进行的,目的是使读者对CPU工作原理有一个清晰、直观的认识,为汇编语言的学习打下基础。其中隐蔽了CPU的物理结构以及具体的工作细节)。
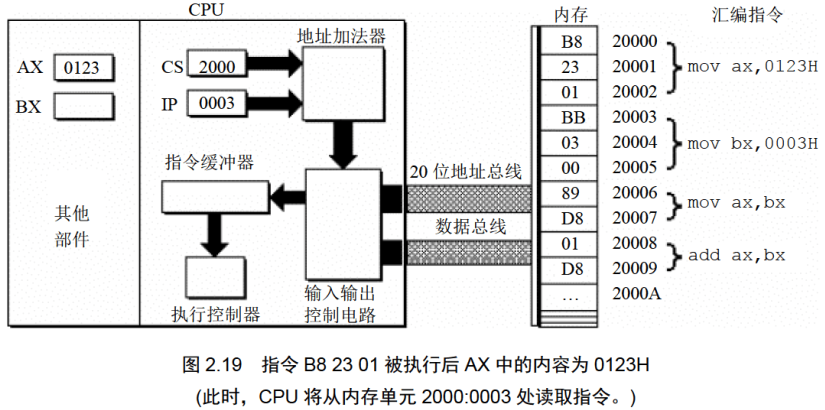
下面的一组图(图2.20〜图2.26),以图2.19的情况为初始状态,展示了8086CPU继续读取、执行3条指令的过程。
注意IP的变化(下面的描述中,隐蔽了读取每条指令的细节)。
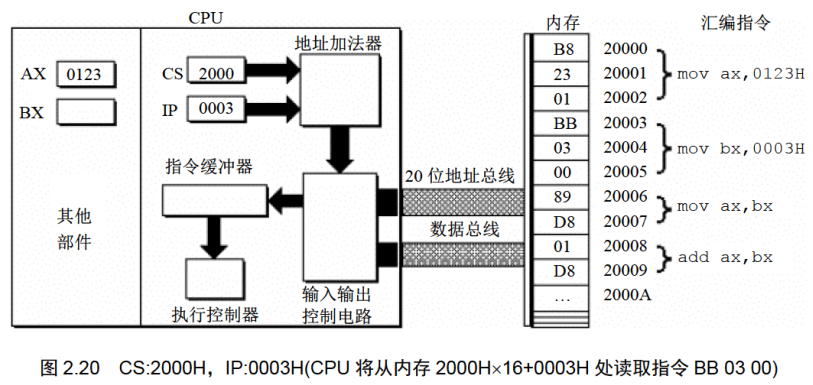
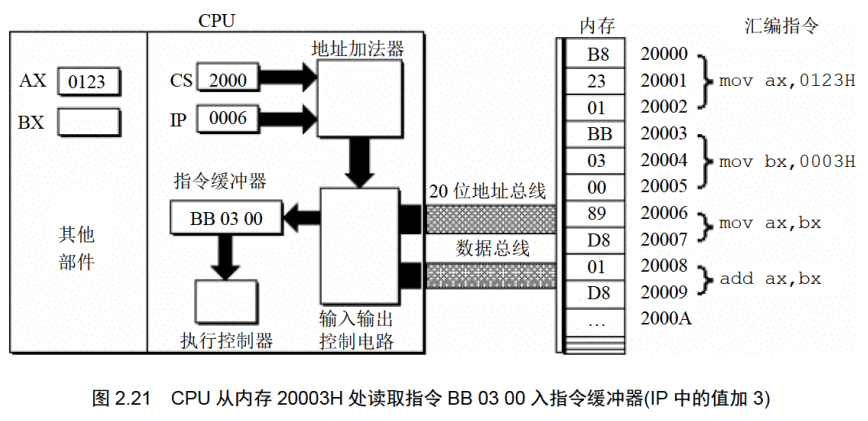
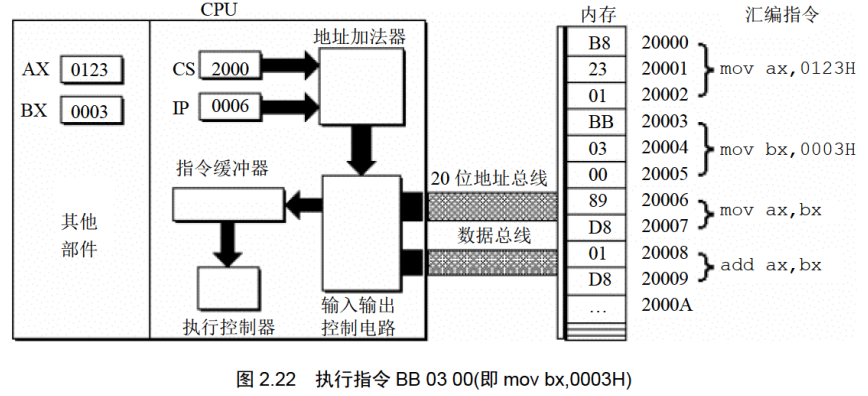
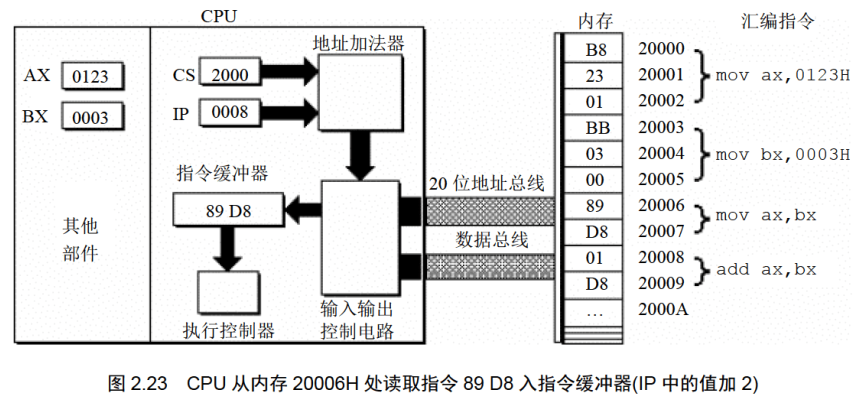
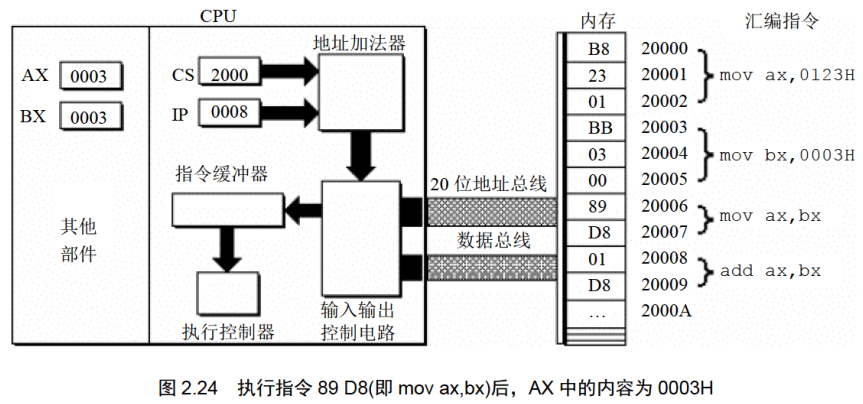
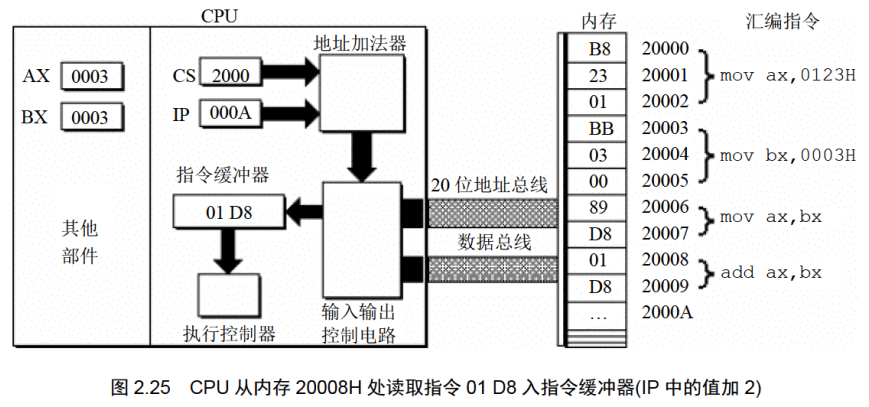
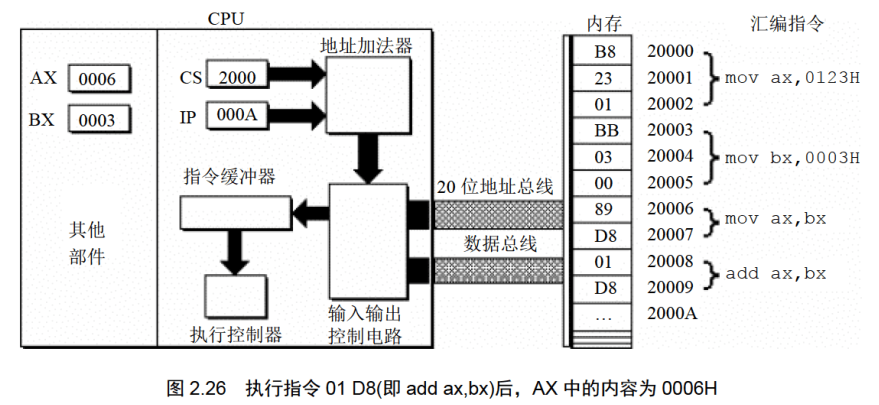
通过上面的过程展示,8086CPU的工作过程可以简要描述如下。
(1)从CS:IP指向的内存单元读取指令,读取的指令进入指令缓冲器;
(2)IP=IP+所读取指令的长度,从而指向下一条指令;
(3)执行指令。转到步骤(1),重复这个过程。
现在,我们更清楚了CS和IP的重要性,它们的内容提供了CPU要执行指令的地址。
我们在第1章中讲过,在内存中,指令和数据没有任何区别,都是二进制信息,CPU在工作的时候把有的信息看作指令,有的信息看作数据。
现在,如果提出一个问题:CPU根据什么将内存中的信息看作指令?如何回答?
我们可以说,CPU将CS:IP指向的内存单元中的内容看作指令,因为,在任何时候,CPU将CS、IP中的内容当作指令的段地址和偏移地址,用它们合成指令的物理地址,到内存中读取指令码,执行。
如果说,内存中的一段信息曾被CPU执行过的话,那么,它所在的内存单元必然被CS:IP指向过。
CPU从何处执行指令是由CS、IP中的内容决定的,程序员可以通过改变CS、IP中的内容来控制CPU执行目标指令。
我们如何改变CS、IP的值呢?显然,8086CPU必须提供相应的指令。
8086CPU大部分寄存器的值,都可以用mov指令来改变,mov指令被称为传送指令。
但是,mov指令不能用于设置CS、IP的值,原因很简单,因为8086CPU没有提供这样的功能。
能够改变CS、IP的内容的指令被统称为转移指令(我们以后会深入研究)。
我们现在介绍一个最简单的可以修改CS、IP的指令:jmp指令。
若想冋时修改CS、IP的内容,可用形如“jmp 段地址:偏移地址”的指令完成:
jmp 2AE3:3,执行后:CS=2AE3H,IP=OOO3H,CPU将从 2AE33H 处读取指令。jmp 3:0B16,执行后:CS=OOO3H,IP=0B16H,,CPU将从 00B46H 处读取指令。
“jmp 段地址:偏移地址”指令的功能为:用指令中给出的段地址修改CS,偏移地址修改IP。
若想仅修改IP的内容,可用形如“jmp 某一合法寄存器”的指令完成:
jmp ax,指令执行前:ax=1000H,CS=2000H,IP=0003H指令执行后:ax=1000H,CS=2000H,IP=1000Hjmp bx,指令执行前:bx=0B16H,CS=2000H,IP=0003H指令执行后:bx=0B16H,CS=2000H,IP=0B16H
“jmp 某一合法寄存器”指令的功能为:用寄存器中的值修改IP。
jmp ax,在含义上好似:mov IP,ax 。
我们在适当的时候,会用己知的汇编指令的语法来描述新学的汇编指令的功能。
采用一种“用汇编解释汇编”的方法来使读者更好地理解汇编指令的功能,这样做有助于读者进行知识的相互融会。
要强调的是,我们是用“已知的汇编指令的语法”进行描述,并不是用“己知的汇编指令”来描述。
比如,我们用mov IP,ax 来描述jmp ax,并不是说真有mov IP,ax 这样的指令,而是用mov指令的语法来说明jmp指令的功能。
我们可以用同样的方法描述jmp 3:01B6 的功能:jmp 3:01B6 在含义上好似 mov CS,3 mov IP,01B6 。
8086PC机中编程时候,可以根据需要,将一组内存单元定义为一个段。
我们可以将长度为N(N